
本篇文章给大家谈谈hadoop搭建教程,以及hadoop分布式集群搭建对应的知识点,希望对各位有所帮助,不要忘了收藏本站喔。
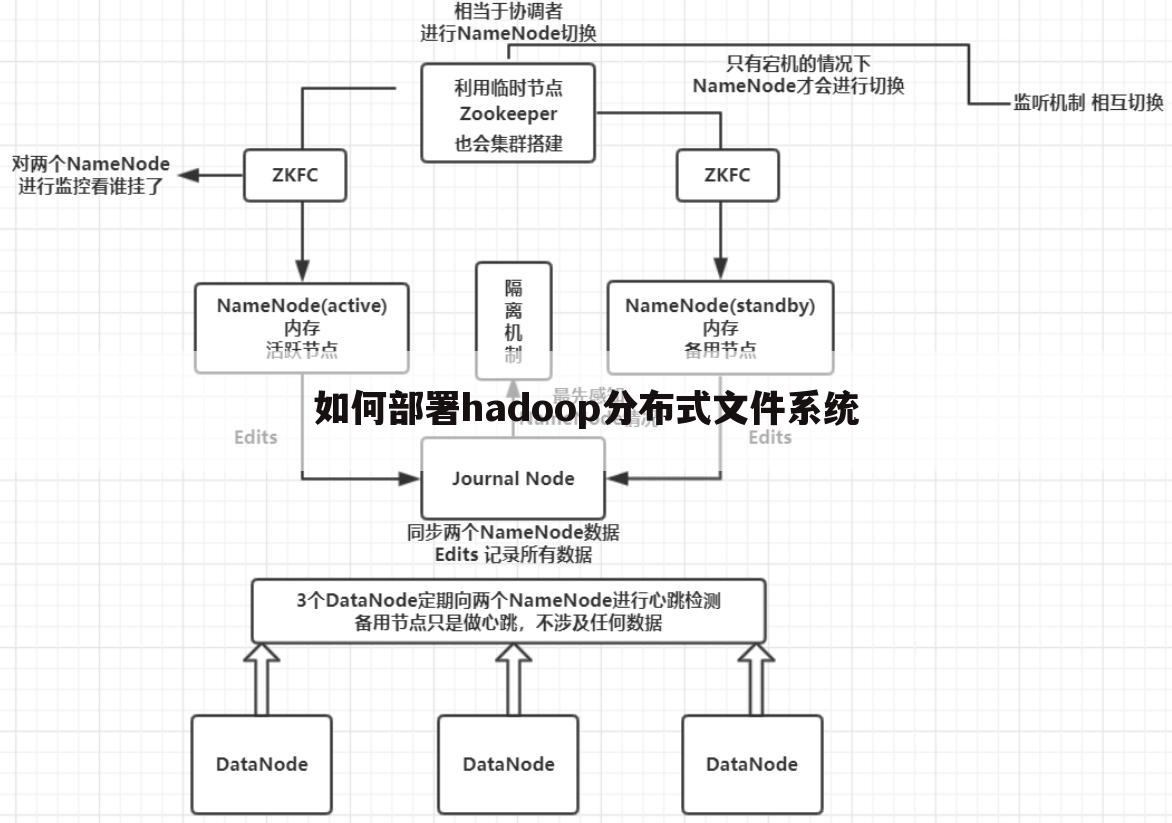
如何部署hadoop分布式文件系统
本文最佳回答用户:【处于被动状态】 ,现在由重庆云诚科技小编为你解答与【hadoop搭建教程】的相关内容!
最佳答案一、实战环境
系统版本:CentOS 5.8x86_64
JAVA版本:JDK-1.7.0_25
Hadoop版本:hadoop-2.2.0
192.168.149.128namenode (充当namenode、secondary namenode和ResourceManager角色)
192.168.149.129datanode1 (充当datanode、nodemanager角色)
192.168.149.130datanode2 (充当datanode、nodemanager角色)
二、系统准备
1、Hadoop可以从Apache官方网站直接下载最新版本Hadoop2.2。官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译。(如果是真实线上环境,请下载64位hadoop版本,这样可以避免很多问题,这里我实验采用的是32位版本)
1234 Hadoop
Java
2、我们这里采用三台CnetOS服务器来搭建Hadoop集群,分别的角色如上已经注明。
第一步:我们需要在三台服务器的/etc/hosts里面设置对应的主机名如下(真实环境可以使用内网DNS解析)
[root@node1 hadoop]# cat /etc/hosts
# Do not remove the following line, or various programs
# that require network functionality will fail.
127.0.0.1localhost.localdomain localhost
192.168.149.128node1
192.168.149.129node2
192.168.149.130node3
(注* 我们需要在namenode、datanode三台服务器上都配置hosts解析)
第二步:从namenode上无密码登陆各台datanode服务器,需要做如下配置:
在namenode 128上执行ssh-keygen,一路Enter回车即可。
然后把公钥/root/.ssh/id_rsa.pub拷贝到datanode服务器即可,拷贝方法如下:
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.149.129
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.149.130
三、Java安装配置
tar -xvzf jdk-7u25-linux-x64.tar.gz &&mkdir -p /usr/java/ ; mv /jdk1.7.0_25 /usr/java/ 即可。
安装完毕并配置java环境变量,在/etc/profile末尾添加如下代码:
export JAVA_HOME=/usr/java/jdk1.7.0_25/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVE_HOME/lib/dt.jar:$JAVE_HOME/lib/tools.jar:./
保存退出即可,然后执行source /etc/profile 生效。在命令行执行java -version 如下代表JAVA安装成功。
[root@node1 ~]# java -version
java version "1.7.0_25"
Java(TM) SE Runtime Environment (build 1.7.0_25-b15)
Java HotSpot(TM) 64-Bit Server VM (build 23.25-b01, mixed mode)
(注* 我们需要在namenode、datanode三台服务器上都安装Java JDK版本)
四、Hadoop版本安装
官方下载的hadoop2.2.0版本,不用编译直接解压安装就可以使用了,如下:
第一步解压:
tar -xzvf hadoop-2.2.0.tar.gz &&mv hadoop-2.2.0/data/hadoop/
(注* 先在namenode服务器上都安装hadoop版本即可,datanode先不用安装,待会修改完配置后统一安装datanode)
第二步配置变量:
在/etc/profile末尾继续添加如下代码,并执行source /etc/profile生效。
export HADOOP_HOME=/data/hadoop/
export PATH=$PATH:$HADOOP_HOME/bin/
export JAVA_LIBRARY_PATH=/data/hadoop/lib/native/
(注* 我们需要在namenode、datanode三台服务器上都配置Hadoop相关变量)
五、配置Hadoop
在namenode上配置,我们需要修改如下几个地方:
1、修改vi /data/hadoop/etc/hadoop/core-site.xml 内容为如下:
<xml version="1.0">
<xml-stylesheet type="text/xsl"href=\'#\'" Put site-specific property overrides inthisfile. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.149.128:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base forother temporary directories.</description>
</property>
</configuration>
2、修改vi /data/hadoop/etc/hadoop/mapred-site.xml内容为如下:
<xml version="1.0">
<xml-stylesheet type="text/xsl"href=\'#\'" Put site-specific property overrides inthisfile. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.149.128:9001</value>
</property>
</configuration>
3、修改vi /data/hadoop/etc/hadoop/hdfs-site.xml内容为如下:
<xml version="1.0"encoding="UTF-8">
<xml-stylesheet type="text/xsl"href=\'#\'" /name>
<value>/data/hadoop/data_name1,/data/hadoop/data_name2</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/data_1,/data/hadoop/data_2</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4、在/data/hadoop/etc/hadoop/hadoop-env.sh文件末尾追加JAV_HOME变量:
echo "export JAVA_HOME=/usr/java/jdk1.7.0_25/">> /data/hadoop/etc/hadoop/hadoop-env.sh
5、修改 vi /data/hadoop/etc/hadoop/masters文件内容为如下:
192.168.149.128
6、修改vi /data/hadoop/etc/hadoop/slaves文件内容为如下:
192.168.149.129
192.168.149.130
如上配置完毕,的配置具体含义在这里就不做过多的解释了,搭建的时候不明白,可以查看一下相关的官方文档。
如上namenode就基本搭建完毕,接下来我们需要部署datanode,部署datanode相对简单,执行如下操作即可。
1 fori in`seq 129130` ; doscp -r /data/hadoop/ root@192.168.149.$i:/data/ ; done
自此整个集群基本搭建完毕,接下来就是启动hadoop集群了。
以上就是重庆云诚科技小编解答(处于被动状态)解答关于“如何部署hadoop分布式文件系统”的答案,接下来继续为你详解体育用户(西瓜贩子)回答“怎样在linux系统上搭建Hadoop集群?”的一些相关解答,希望能解决你的问题!
怎样在linux系统上搭建Hadoop集群?
本文最佳回答用户:【西瓜贩子】 ,现在由重庆云诚科技小编为你解答与【hadoop搭建教程】的相关内容!
最佳答案(1)下载jdk,在官网下载,下载rpm的包
(2)hadoop包的下载,官网上下载
download hadoop->release->mirror site(镜像站)->随便选择离自己近的(HTTP下的第一个)->选择2.7.2->下载.tar.gz
(3)将两个包远程传输到linux虚拟机中
(4)将主机名和ip地址进行适配,让我们的ip地址和主机名(如bigdata)相匹配:写到/etc/hosts里面
vi /etc/hosts
按“i”进入插入状态 将原有的地址注释掉
在新的一行输入:ip地址 主机名(如172.17.171.42 bigdata)(注:可以双击xshell的窗口再打开一个连接窗口,可以在新的窗口查询ip地址并进行复制)
按“Esc”退出插入状态
输入:wq保存退出
修改完之后可以输入hostname回车,查看是否成功
reboot:重启,使得刚刚的修改生效
(5)将包放到opt下:cp hadoop-2.7.2.tar.gz /opt/
cp jdk-8u111-linux-x64.rpm /opt/
进入opt:cd /opt/
查看opt下的文件:ll
(6)安装jdk,配置jdk的环境变量
安装命令:rpm -ivh jdk-Bu101-linux-x64.rpm
配置环境变量:进入profile进行编辑:vi /etc/profile
并按照上面的方式在最后写入并保存:JAVA_HOME=/usr/java/default/(/usr/java/default/是jdk的安装目录)
打印JAVA_HOME检验是否配置好:echo $JAVA_HOME结果发现打印出来的没有内容因为我们对/etc/profile的修改需要通过以下命令对它生效source /etc/profile。再次输入echo $JAVA_HOME,打印结果为/usr/java/default/
(7)验证jdk安装好:java -version
(8)配置SSH(免密码登录)
回到根目录:cd 安装SSH秘钥:ssh-keygen -t rsa会自动在/root/.shh/目录下生成
查看目录:ll .ssh/有两个新生成的文件id_rsa(私钥),id_rsa.pub(公钥)
进入.ssh/:cd .ssh/
将公钥写入authorized_key中:cat id_rsa.pub >> authorized_keys
修改authorized_keys文件的权限:chmod 644 authorized_keys
修改完后退出.ssh的目录cd进入初始目录输入:ssh bigdata(bigdata为你要远程登录的主机名或者ip地址)第一次登录需要确认是否需要继续登录输入yes继续登录
退出exit
(9)安装及配置hadoop
解压:tar zxf hadoop-2.7.2.tar.gz
查看/opt目录下是否已经存在解压的文件:ll(结果为出现hadoop-2.7.2)
继续查看hadoop-2.7.2里的内容:cd hadoop-2.7.2
配置HADOOP_HOME:修改/etc/profile
进入hadoop的配置文件目录cd /opt/hadoop-2.7.2/etc/hadoop/,会用的的配置文件如下:
core-site.xml
配置hadoop的文件系统即HDFS的端口是什么。
配置项1为default.name,值为hdfs://bigdata:9000(主机名:bigdata也可也写成ip地址,端口9000习惯用)
配置项2为hadoop临时文件,其实就是配置一个目录,配置完后要去创建这个目录,否则会存在问题。
配置项3分布式文件系统的垃圾箱,值为4320表示3分钟回去清理一次
<property>
<name>fs.default.name</name>
<value>hdfs://bigdata:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.2/current/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>
hdfs-site.xml
配置项1,namenode的细节实际上就是一个目录
配置项2,datanode的细节,真实环境中datanode的内容不需要再namenode的系统下配置,在此配置的原因是我们的系统是伪分布式系统,namenode和datanode在一台机器上
配置项3,副本的数量,在hdfs中每个块有几个副本
配置项4,HDFS是否启用web
配置项5,HDFS的用户组
配置项6,HDFS的权限,现在配置为不开启权限
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.2/current/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.7.2/current/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>staff</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
创建配置文件中不存在的目录:mkdir -p /opt/hadoop-2.7.2/current/data
mkdir -p /opt/hadoop-2.7.2/current/dfs/name
mkdir -p /opt/hadoop-2.7.2/current/tmp
yarn-site.xml
配置项1,resourcemanager的hostname,值为你运行的那台机器的主机名或IP地址
配置项2,nodemanager相关的东西
配置项3,nodemanager相关的东西
配置项4,resourcemanager的端口,主机名+端口号(IP+端口)
配置项5,resourcemanager调度器的端口
配置项6,resourcemanager.resource-tracker,端口
配置项7,端口
配置项8,端口
配置项9,日志是否启动
配置项10,日志保留的时间长短(以秒为单位)
配置项11,日志检查的时间
配置项12,目录
配置项13,目录的前缀
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bigdata:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bigdata:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bigdata:18025</value>
</property> <property>
<name>yarn.resourcemanager.admin.address</name>
<value>bigdata:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bigdata:18088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
mapred-site.xml
没有mapred-site.xml,输入vi mapred-按“TAB”发现有mapred-site.xml.template,对该文件进行复制
cp mapred-site.xml.template mapred-site.xml 配置项1,mapreduce的框架
配置项2,mapreduce的通信端口
配置项3,mapreduce的作业历史记录端口
配置项4,mapreduce的作业历史记录端口
配置项5,mapreduce的作业历史记录已完成的日志目录,在hdfs上
配置项6,mapreduce中间完成情况日志目录
配置项7,mapreduce的ubertask是否开启
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>bigdata:50030</value>
</property>
<property>
<name>mapreduce.jobhisotry.address</name>
<value>bigdata:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/jobhistory/done</value>
</property>
<property>
<name>mapreduce.intermediate-done-dir</name>
<value>/jobhisotry/done_intermediate</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
slaves
bigdata
hadoop-env.sh
JAVA_HOME=/usr/java/default/
格式化分布式文件系统(hdfs):hdfs namenode -format
成功的标志: INFO common.Storage: Storage directory /opt/hadoop-2.7.2/current/dfs/namehas been successfully formatted.
启动Hadoop集群:/opt/hadoop-2.7.2/sbin/start-all.sh
验证Hadoop集群是否正常启动:
jps,系统中运行的java进程;
通过端口查看(关闭防火墙或者service iptables stop在防火墙的规则中开放这些端口):
,分布式文件系统hdfs的情况
yarn
关于[hadoop搭建教程]的介绍就聊到这里吧,感谢你花时间阅读本站内容,更多关于hadoop搭建教程、hadoop分布式集群搭建的信息别忘了在本站进行查找喔。
推荐文章:
本文由网上采集发布,不代表我们立场,转载联系作者并注明出处:https://www.cqycseo.com/zixun/185.html
